揭秘大廠都在用的數(shù)據(jù)倉庫 處理萬億級數(shù)據(jù)的神器
在當今數(shù)據(jù)驅(qū)動的時代,企業(yè)每天產(chǎn)生的數(shù)據(jù)量呈指數(shù)級增長,尤其是大型互聯(lián)網(wǎng)公司,其業(yè)務(wù)數(shù)據(jù)動輒達到千億甚至萬億級別。如何高效、可靠地存儲、處理和分析這些海量數(shù)據(jù),成為決定企業(yè)競爭力的關(guān)鍵。數(shù)據(jù)倉庫,尤其是面向大規(guī)模數(shù)據(jù)處理的服務(wù)與架構(gòu),正是應(yīng)對這一挑戰(zhàn)的“神器”。本文將深入揭秘大廠普遍采用的數(shù)據(jù)倉庫核心技術(shù)、架構(gòu)模式及其數(shù)據(jù)處理服務(wù),解析它們?nèi)绾务{馭萬億級數(shù)據(jù)洪流。
一、 數(shù)據(jù)倉庫的演進:從傳統(tǒng)到云原生
傳統(tǒng)的數(shù)據(jù)倉庫(如Teradata、Oracle Exadata)雖然在結(jié)構(gòu)化數(shù)據(jù)分析上表現(xiàn)出色,但其擴展性差、成本高昂,難以應(yīng)對互聯(lián)網(wǎng)時代的非結(jié)構(gòu)化、半結(jié)構(gòu)化數(shù)據(jù)及實時分析需求。這催生了以Hadoop生態(tài)為基礎(chǔ)的大數(shù)據(jù)平臺。Hadoop體系復雜,運維難度大。
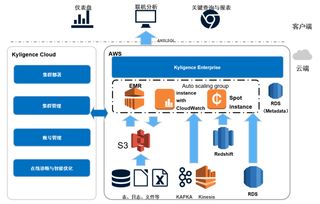
如今,大廠的主流選擇已轉(zhuǎn)向云原生數(shù)據(jù)倉庫。這類服務(wù)將計算與存儲分離,實現(xiàn)了近乎無限的彈性擴展,并按需付費,完美平衡了性能、靈活性與成本。代表產(chǎn)品包括:
- Snowflake:完全云原生,支持跨云部署,自動管理計算資源。
- Amazon Redshift:AWS的托管數(shù)據(jù)倉庫服務(wù),深度集成其云生態(tài)。
- Google BigQuery:無服務(wù)器架構(gòu),用戶無需管理基礎(chǔ)設(shè)施,直接執(zhí)行SQL查詢海量數(shù)據(jù)。
- 國內(nèi)阿里云的MaxCompute、騰訊云的TBaaS等:同樣提供強大的彈性計算與存儲能力。
二、 核心架構(gòu)揭秘:如何支撐萬億級處理
處理萬億級數(shù)據(jù)并非單點技術(shù)突破,而是一套精心設(shè)計的架構(gòu)體系。
- 存算分離與彈性伸縮:這是云原生數(shù)據(jù)倉庫的基石。數(shù)據(jù)存儲在廉價、高可用的對象存儲(如AWS S3)中,計算集群則根據(jù)查詢負載動態(tài)創(chuàng)建或銷毀。這意味著在無查詢時計算成本可降為零,而在需要時能瞬間調(diào)動成千上萬個核心進行并行計算,處理PB級數(shù)據(jù)只需秒級響應(yīng)。
- 大規(guī)模并行處理(MPP)架構(gòu):查詢?nèi)蝿?wù)被分解成多個子任務(wù),在數(shù)百甚至數(shù)千個計算節(jié)點上同時執(zhí)行,最后匯果。這種“分而治之”的思想是處理海量數(shù)據(jù)速度的關(guān)鍵。
- 列式存儲與高效壓縮:與傳統(tǒng)的行式存儲不同,列式存儲將同一列的數(shù)據(jù)連續(xù)存放。這對于分析型查詢(通常只涉及部分列)極為高效,能大幅減少I/O。同類數(shù)據(jù)更容易壓縮,有時壓縮比可達10:1以上,極大地節(jié)省了存儲成本和網(wǎng)絡(luò)傳輸開銷。
- 智能查詢優(yōu)化與執(zhí)行:先進的優(yōu)化器會自動重寫查詢邏輯、選擇最佳連接順序和執(zhí)行路徑,甚至利用數(shù)據(jù)統(tǒng)計信息(如最小值、最大值、直方圖)跳過無關(guān)的數(shù)據(jù)塊(謂詞下推、分區(qū)裁剪),避免“全表掃描”的性能災難。
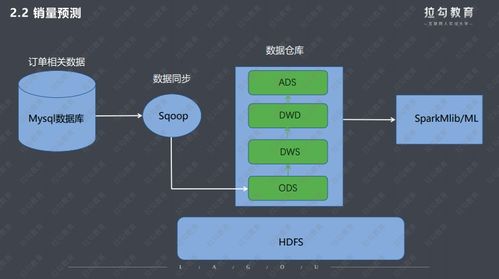
- 分層數(shù)據(jù)架構(gòu)與數(shù)據(jù)湖倉一體化:大廠通常采用分層的模型(如ODS->DWD->DWS->ADS),將原始數(shù)據(jù)逐步清洗、整合、匯總,形成易于分析的維度模型。趨勢是融合數(shù)據(jù)湖的靈活性與數(shù)據(jù)倉庫的管理性,形成“湖倉一體”(Lakehouse),在同一個存儲層上支持BI、機器學習、實時流處理等多種工作負載。
三、 關(guān)鍵數(shù)據(jù)處理服務(wù)與生態(tài)
圍繞核心數(shù)據(jù)倉庫,一系列配套的數(shù)據(jù)處理服務(wù)構(gòu)成了完整的數(shù)據(jù)流水線:
- 數(shù)據(jù)集成與同步:使用CDC(變更數(shù)據(jù)捕獲) 工具(如Debezium)實時捕獲數(shù)據(jù)庫變更,或通過批量ETL/ELT工具(如Apache Airflow, dbt, DataWorks)將分散的業(yè)務(wù)數(shù)據(jù)定時匯聚到數(shù)據(jù)倉庫。
- 實時流處理:對于需要實時響應(yīng)的場景(如監(jiān)控、風控),Apache Flink 和 Apache Kafka 的組合成為標配。它們能處理高速數(shù)據(jù)流,并進行復雜的事件計算,結(jié)果可實時寫入數(shù)據(jù)倉庫或下游應(yīng)用。
- 數(shù)據(jù)治理與質(zhì)量:元數(shù)據(jù)管理、數(shù)據(jù)血緣、數(shù)據(jù)質(zhì)量監(jiān)控(如發(fā)現(xiàn)空值、異常值)是保障數(shù)據(jù)可信度的關(guān)鍵。大廠會自研或采用專業(yè)平臺來確保“數(shù)據(jù)資產(chǎn)”的清晰、準確和安全。
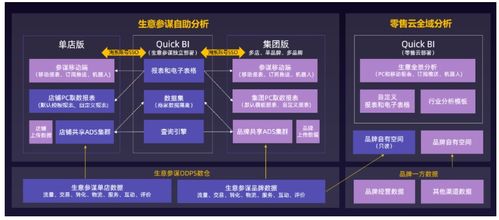
- BI與可視化:處理好的數(shù)據(jù)通過Superset、Tableau、Quick BI等工具,以報表、儀表盤的形式提供給業(yè)務(wù)和決策者,驅(qū)動運營和增長。
四、 實踐挑戰(zhàn)與未來展望
盡管技術(shù)先進,大廠在實踐中也面臨挑戰(zhàn):成本控制(避免“跑飛”的查詢消耗巨額資源)、數(shù)據(jù)安全與隱私合規(guī)、多源異構(gòu)數(shù)據(jù)的統(tǒng)一管理、以及不斷降低數(shù)據(jù)分析的“時間到洞察”的延遲。
數(shù)據(jù)倉庫的發(fā)展將更加智能化與自動化:
- AI增強:利用機器學習自動優(yōu)化查詢性能、進行異常檢測、甚至推薦數(shù)據(jù)洞察。
- 無縫體驗:進一步模糊數(shù)據(jù)湖、數(shù)據(jù)倉庫、機器學習平臺之間的界限,提供統(tǒng)一的數(shù)據(jù)訪問與計算接口。
- 實時化:支持更低的端到端數(shù)據(jù)延遲,從“T+1”的批處理邁向真正的實時分析與決策。
###
處理萬億級數(shù)據(jù)的數(shù)據(jù)倉庫,已從昂貴笨重的“重型機械”進化為靈活彈性的“云上智能引擎”。它不僅是存儲數(shù)據(jù)的倉庫,更是整合了計算、管理、服務(wù)的數(shù)據(jù)處理中樞。理解其架構(gòu)與生態(tài),對于任何希望在大數(shù)據(jù)時代構(gòu)建核心競爭力的組織而言,都至關(guān)重要。大廠們的實踐表明,唯有通過持續(xù)的技術(shù)架構(gòu)演進和精細化的數(shù)據(jù)運營,才能真正將海量數(shù)據(jù)轉(zhuǎn)化為驅(qū)動業(yè)務(wù)增長的寶貴資產(chǎn)。
如若轉(zhuǎn)載,請注明出處:http://m.cloud360.org.cn/product/14.html
更新時間:2026-05-19 06:57:43